My Linux box has a M2 NVME drive with standard stuff, but bigger files go on two hard drives in a RAID1 (mirrored). A few months ago, one of the drives fell off the RAID, which usually means it failed. Luckily when one drive fails in a RAID1, the content continues to be available.
At that time, I just bought a new drive, swapped it in for the old one, and then added it to the RAID and then it automatically resynchronized. No muss, no fuss, no bother.
But a few days ago, I noticed that the SMART monitor on the other hard drive was showing some errors. I guess it makes sense that if one drive fails after 6 years, it’s not too surprising that the other one does as well. It hadn’t failed off the RAID yet, but I figured I’d be proactive. I ordered a new hard drive, figuring it would be as simple as last time.
And of course, this time it wasn’t that simple. After swapping the drive, the box wouldn’t boot, because the BIOS didn’t recognize the M2 NVME drive as a bootable drive. It showed up in the NVME configuration menu of the BIOS, but I couldn’t add it to the boot menu. I tried the “update the BIOS over the network using a PXE boot, but it just hung up and didn’t work. But that option had put the PXE boot options in the boot priority menu, and wouldn’t let me add anything else until I disabled all boot options. So I fiddled a few BIOS configurations (I think I turned off support for some AMI special NVME mode and turned on some boot thing that I had no idea about), and rebooted, and this time it booted. But now the command I used last time, mdadm /dev/md0 --add /dev/sdb failed because the RAID was inactive. So after a bit of googling and a bit of experimenting, I found the combination that worked:
mdadm -A --run /dev/md0 /dev/sda
mdadm /dev/md0 --add /dev/sdb
The first command re-assembled the RAID with just the first drive in it, and the run option to make it make it active even though it doesn’t have both drives. The second command then adds the second drive. I couldn’t put both drives in the first command because when I tried it said that the new drive wasn’t formatted or whatever for RAID.
So now the RAID is happily resynchronizing and I’ve got no SMART errors showing up in my munin console. So all is right in the world. Now if only I could convert the RAID box I have on my Mac Studio from a RAID0 (interleaved for maximum speed) to a RAID5 (safer for long term storage) without paying $150 for a new license for SoftRAID.
Both my home server, and my VPS (Virtual Private Server) need updates. My home server uses Kubuntu 22.04 LTS, and the current version is 25.04 (or 24.04 if I want to stick to LTS, which I probably should). My VPS is on Debian 10.13 (buster), and the current stable version is 12 (bookworm). Both are nagging me that the version they’re running is no longer supported and I should upgrade ASAP.
Ok, for the Kubuntu machine, there’s an update program. But when I run it
sudo do-release-upgrade
I get a message that says
The package 'postgresql-14-postgis-3' is marked for removal but it is in the removal denial list.
I think that means I need to remove PostGIS and try again, and then hopefully reinstall PostGIS after the update. But I’m reluctant to do so, in case it breaks something. I guess I need to bite the bullet and do it.
My VPS was originally Debian 5, and over the years I’ve upgraded it many times just by editing the /etc/apt/sources.list to the new release name, and running
sudo apt update
sudo apt upgrade
But when I contacted Linode technical support about something else, they were horrified that I appeared to them to be using Debian 5. When I told them what I’d done, they were even more horrified. Evidently the proper way update is to spin up a new VPS instance with their Debian 12 image, and then migrate applications and files over. I’d worry about missing something. On the other hand, it might be a chance to leave behind the cruft of things I no longer need.
I guess I’ll start with the local server by removing PostGIS and proceeding from there. For the VPS, I might try just cloning the VPS and doing the old fashioned way.
Since the last time I wrote about it, we’ve been camping 3 times.
Fair Haven State Park
Fair Haven is a pretty short drive, a little more than an hour. We drove through an incredibly intense rain storm and I got utterly drenched sprinting across from the parking lot to the camp office to check in. The rain had pretty much ended by the time we got to our campsite. When we arrived, many of the campsites were quite flooded. Our trailer pad was fine, but much of the grassy area around it was soaked. The water spigot was just across the road from our campsite and it was surrounded by a puddle 8 feet across and just over ankle deep. We stopped before we backed into our site and filled the fresh tank from it, which involved me taking off my shoes and wading across to the tap. Our “loop” of the campsite was at the top of a bluff, and it dried out pretty quickly after we’d got set up.
The site had electricity, but no other services. We took the dogs for a walk around the loop and met one or two of the other campers. One of them had “accosted” us while we were filling our fresh tank telling us about how terrible the water had tasted from that very spigot, which got me very worried because I hadn’t tasted it before filling up. Turns out it tasted fine. I suspect her problem was the age of her camper and the plumbing therein. Later walking around the campsite her husband also accosted us to show us pictures on his phone of some birds he’d seen while he was fishing. I don’t know how it does it, but RVing makes me so chill I find these sorts of encounters funny instead of irritating.
During our four days there, we walked the dogs several times, rode our bikes (even managed to climb the bluff we’re on top of), and went into town for a meal. We ate at the dive-iest dive bar you’ve ever seen. The place looked like you’d probably get stabbed if you were there after dark, but they had an amazing selection of hard liquors and the lady behind the bar loved to talk. Again, I’m RV-chill and Vicki is always chill so we had fun talking to her.
On the second or third day I had to refill the fresh tank – when I’d been filling on pulling in I’d been distracted by the lady with the bad taste problem and had stopped filling when the vent had started gurgling instead of waiting until the water was coming out the vent so it wasn’t completely full. I tried to reach across the road with our two fresh water hoses but came up a few feet short, so we semi-packed up and hitched up and dragged the trailer a few feet closer. I can’t remember if it was the same “trip”, but we also made a trip to the dump station because the grey tank was getting worryingly full. I really have to wonder about the logic of making the grey tank only 60% as big as the fresh tank when most of your water ends up going down the sink and shower drains.
Anyway it was a nice park with a beach on the lake and a small pond and lots of trails and not too far away so I’d like to go back.
Little Wolf Beach and Campground
Our next trip after that was another trip to a canoe/kayak race, the Tupper Lake 8 Miler. The organizer was Roger G and I’d kind of promised him I’d come and do drone video of his race when we’d talked at the Round the Mountain race.
Little Wolf Beach and Campground is owned by the town of Tupper Lake. Although it’s on a pretty little lake, it’s one of those “cheek by jowl” RV parks where every campsite is barely wide enough for your trailer and a picnic table. On the other hand, it has full hookups. I like full hookups.
Videoing the race went really well. It was brilliant sunshine, the race was extremely well attended, and I got some good footage. I followed the starters for the first 1,000 yards or so, then packed up and headed out in my truck. I was hoping to get to a bridge on a private road that was about 1/3rd of the way on the out and back course, so I was hoping to get paddlers on the way out as well as the way back. Unfortunately the route to the bridge was blocked by a locked gate. Plan B was to get to a point near the turn-around point, but after creeping down a very rough private road, I found the cabin at that spot was occupied and I didn’t want to answer questions about why I was on their private road so I turned around. Instead I headed to a very long dock that goes well into the river. Unfortunately it was about a mile from the start and finish so I didn’t see the outgoing paddlers, and I barely got set up in time to get the first returning paddlers. Three of the fastest paddlers in the state were together in a K-3 and attempting to beat the course record, which was set the previous year by two of those three in a K-2. I got most of the returning paddlers (missing one or two because I was out of position or doing a battery change) but I ran out of battery as what I think was the last paddler was coming through.
After I decided to use the RV to travel to races to video them, I bought a laptop and an external SSD drive. This allowed me to start editing the video while I’m in the RV, then move the SSD to my home setup and put the finishing touches and upload it to YouTube when I get home.
Tupper Lake 8 Miler Video
One of the nights there was a torrential thunderstorm. I was really glad to be in a trailer instead of a tent. When we walked the dogs the next morning, we noticed that all the tents that had been in the non-RV part of the campground seem to have vanished overnight. The campground is on sandy soil, so it was dry and well drained, and it was amusing to see that both tiny ant hills and ant-lion tunnel traps had reappeared in great numbers.
It was scorching hot in the days after the race, so mostly I was content to just sit inside and edit my video. However, Vicki needed to go into town to buy some groceries – we’d had a bit of a checklist failure and some of the things we’d planned to eat didn’t get loaded into the trailer before we left. I took the time to do a full flush of the tanks. Especially the black tank. I flushed, added a few gallons of water via the tank flush valve, and flushed again. I repeated that 7 or 8 times, until I finally stopped seeing any brown water or shreds of toilet paper. One thing about RVing is you get very aware of where your utilities come from and where they go.
It wasn’t the greatest place for walking or biking around, but again it was so hot neither us nor the dogs really felt like it.
On the drive home, it was very hot. The truck started making a very high pitched whine, especially when climbing hills. Since we’re kind of skirting very close to (or possibly over) the line of how much we’re legally allowed to pull with the truck, I’m very scared that I’m damaging the truck. On the other hand, I’ve never owned a truck or a diesel or a turbo charged vehicle before, so I don’t know what is normal. My brother suggested there might be vibration in the hoses going to or from the turbo charger. I opened the hood (usually a very bad idea, considering my track record) and I did find one bolt that looked like it was supposed to be holding down one of the hoses, and it was missing a nut. I was fortunate to have a nut in my toolbox that was the exact right size but the wrong thread pitch, so I took it to the local hardware store and got one that was correct. Unfortunately I couldn’t test whether that fixed it because I only heard the noise when towing the trailer and the trailer had already gone back to the storage yard.
Scogog Landing
Scogog is a medium sized lake north of Oshawa and Pickering. Last time we went up to Canada to see my kids (and their kids) we stayed at Darlington Provincial Park, which was a really nice campsite, but this time it didn’t have any spots left, so Vicki found this campground. It had some terrible reviews, but a year or two ago it changed names and the reviews got way better, so I guess somebody poured some money into it.
Driving up, I discovered that the magic nut that I’d replaced on the truck hadn’t fixed the whine problem, although maybe it had removed one element of it? Hard to tell. The truck didn’t seem to be suffering, though, so maybe we’ll be ok.
It only has 11 spots for transient RVs on one side of an inlet on the lake (with electrical and water, but no sewer), and on other other side of the inlet they have what looks like at least a hundred and possibly more “seasonal” RV spots. This is where RVs go to die. I didn’t see a single one that wasn’t anchored down by decks, gardens, fences, and other signs that they never move. And some of them aren’t even RVs, they’re more like manufactured homes. I suppose they’re called “seasonal” because they don’t plow the snow in the winter, but it looks like most people probably spend the entire summer, or at least most weekends there. They also have a very basic restaurant, that actually had live entertainment on the Saturday night we were there. There were also a community hall and they had some programs on for kids during the day and adults in the evening. And an area with a couple of outdoor pools and playground equipment. So yeah, probably a nice place for kids before they get too addicted to social media.
It took me about 11 backs and forths to get the trailer aligned into the spot, because the spots are narrow and there isn’t much room on the other side to forward into without either hitting dock furniture or going into the inlet. Our spot had a telephone pole just off the camp side of the trailer pad, which I actually tapped when maneuvering (and discovered later that I’d knocked a piece off the awning machinery cover).
So it was a massive hit on my RV chill the next morning when Vicki told me I had move the trailer forward a bit so there’s room to open the awning because of that stupid telephone pole. So we disconnected (but didn’t put away) the electrical cord and water hose, put the slider in, raised the jacks, removed the chocks and levelers and re-hitched. Didn’t bother with the weight distribution bars. Pulled forward a couple of feet, but because the trailer hadn’t been exactly aligned with the pad, it took a couple of back and forths to get it positioned right. I don’t know why, but when we dropped the hitch, the trailer leapt to one side, half way off the blocks we put under the tongue jack. There was nothing to do but re-hitch it, try to move it back where it was supposed to be (more back and forths), and then when we dropped the hitch it leapt again, this time completely off the blocks. At this point I said I was done, and we proceeded to re-setup everything.
Afterwards, the kids and grands all came to visit at the trailer. (Side note: out of respect for my grandkids privacy, I’m not going to use their names. My older daughter L has two school aged boys. My younger daughter A has one very young girl.)
The youngest boy (G) found that the inlet had an ample supply of medium sized perch and spent a lot of time flogging them with a fishing line. He even caught a few. He was casting and retrieving with a worm on a hook and a bobber on the line, so if I hadn’t been having a bad pain day I probably should have played the kindly old grandfather and taught him something about fishing. Not that I know a lot, but I did fish a bit when I was a teenager. I was terrible at it and rarely caught anything, and he was catching perch so maybe it’s just as well I kept out of it.
The young girl (M) is still painfully shy around Vicki and I, but I think she is warming up a bit.
After a while at our trailer, we all headed into Port Perry for dinner. The place we originally picked was too full so we headed to another place that wasn’t too expensive but a thousand percent nicer than the place at the campsite. The children’s menu portions were *huge*. My Montjaro-reduced appetite would probably have been sated with the chicken fingers and fries that G had.
That evening, the sinks all backed up, indicating that either the grey tank was full, or there was a vent problem. I didn’t sleep very well worrying about it. The next morning, I went up on the roof and blew down the vent pipe, which caused some big bubbles in the sinks, so I knew the vent wasn’t blocked. At some point, I want to try measuring how much water goes in the grey tank before it starts backing up in the sinks because sometimes people find the manufacturer has put the vent tube too far into the tank which causes a vapor lock where the air in the tank above the bottom of the vent pipe can’t exit. But whether or not that’s happening, at this point we need to hitch up again and drive the trailer over to the dump station. Sigh. At least this time, when we returned I had a better handle on how to back into that spot so it didn’t take too many back and forths. And when we unhitched, the trailer didn’t leap. I wonder if that’s because the previous time we didn’t drive very far so it didn’t release any tension on the hitch, or because we used the weight distribution bars this time.
After we finished dumping the tanks and re-setting our campsite, we met A and her husband and child M in Port Perry again. This time we spent some time poking around shops, eating ice cream and listening to some live music that the Port Perry tourism board provided. It was fun, if a bit hard on my pain levels.
Monday’s drive home was pretty uneventful except we’d had to stop for fuel twice – I’m a cheap bastard at heart and I didn’t want to pay Canadian prices for diesel if I didn’t have to, so I put in barely enough to get back over the border, and then stopped at an OpenRoads stop after we got back to the US.
Miscellaneous Tinkering
During this period, I also did some tinkering in the trailer.
Put some wood strips to keep the batteries from sliding around in the under-bed box
Put a slide-out carrier in one of the panty cupboards
Put a metal holder for the fire extinguisher because the plastic one that came with the fire extinguisher broke
Bought a replacement vent fan for the one in the bathroom, because the installed one has a switch that Vicki can’t easily reach. I haven’t installed it yet because I’m waiting for cooler weather so I’m not working on the roof in 90F weather.
I’ve ordered but not received a portable tank to drain the grey tank into so we don’t have to keep hitching up and dragging the trailer to the dump station
Ok, this is kind of long. I’m too lazy to break this into separate parts, but in the future I’ll try to write more frequently.
I got a pretty late start on paddling this year. It’s not like when I was racing – I remember one year when somebody asked me when my off season was, and I checked Garmin Connect and told them I hadn’t done any paddling between December 16th and January 6th, so I guess that was it. Between the fact that there were no races to train for, and this spring has been rainy and cold, there just weren’t any opportunities.
Today was my third paddle of the season. Last time, I went for 40 minutes and my physiotherapist Emma suggested I stick on that level of effort for a while. But I couldn’t help it – I paddled down for 20 minutes, knowing it would take a bit longer to come back because I’d had a tail wind. But the way back was very hard – I assumed because of the wind. I ended up taking a few breaks, and my shoulders were quite sore. I went into full “Boyan-mode”, paddling with my elbows down and almost no movement in my shoulders. But I was still completely done when I finished. I had to take another break before I could even lift the boat out of the water.
It was only after I got my boat on the roof rack that I noticed the rudder flag. “Hey, I don’t remember putting that on….come to think of it, I don’t remember taking it off…oh, and it’s soaking wet!” Yes, I’d inadvertently given myself some extra drag.
When I was racing, some of the real hard core types would put a rope with a knot or two on it around their boat, or even a couple of tennis balls, just for extra drag and more training effect. Knowing how fragile my shoulders are, there was no way I would participate in this madness. The closest I’d come was to switch to a wider boat, especially when training out on Lake Ontario. A little extra drag, a lot more stability, and I could really put the power down even in waves.
Last weekend (May 9-11) we did an RV trip to the Lake Placid/Saranac Lake area. Originally I’d planned to just do it on my own, because my main purpose for doing it was so I could shoot some drone footage at the ‘Round The Mountain Canoe/Kayak Race. They should probably rename that, because it’s not just canoes and kayaks, it’s also pack boats (a canoe-like boat with a lot of tumblehome so it’s paddled with a kayak paddle – most of them are made by Placid Boat Works) and guide boats (a bigger boat, rowed by one person, and sometimes with a person in the stern with a canoe paddle, based on the boats that Adirondak guides used a hundred years ago) and stand up paddle boards. I thought Vicki would be bored if I dragged her along but not only did she come on the trip, but she came to the race as well.
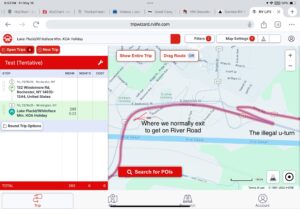
Anyway, we had a rainy drive up on Friday. RVLife once again tried to kill us by trying to route us via an illegal U-turn on a divided highway with almost no median between the directions, just a gap in the fence and a “No U-turns except emergency vehicles” sign. It’s funny, because mere minutes before this we passed an exit that I said “I normally go off here when using Google or Apple Maps, I wonder why RVLife is having us miss it?”
We arrived at the campground just a few minutes late for a normal check in. Some of the KOA people were still hanging around the late check in desk and handed us our mirror tag and camp map with the route to our campsite helpfully drawn in. It was a pull-through site, full service. Something we haven’t had yet this year. I pulled through, and checked our trailer location and declared it in proper position, so we set about leveling and unhitching and putting down the jacks and out the slides. But when it came time to hook up the water service, I discovered that the thing I’d thought was the water spigot was just some other piece of infrastructure, and the spigot was actually on the backside of the electrical post. And wouldn’t you know it, the water hose ended up being 4 feet short. Oh well, I thought, it’s a pain but I guess we’ll have to hitch up again and move the trailer back 4 feet.
That’s when disaster struck. The front set of jacks wouldn’t retract. The relay made a click, but there was no motor sound. So now we’ve got two problems, and no easy way to fix them. The Facebook technical guru Steve was also camping, and both of us had intermittent 1 dot of signal. But he said to try resetting everything, but that didn’t work. Also it turned out that the manual retraction of the jacks uses a proprietary connection, and evidently we didn’t get one with our trailer, or misplaced it. So we decided that we had to get some more drinking water hose.
We drove into Lake Placid and Saranac Lake, and didn’t find any place selling garden hose. We did stop at a grocery store and bought some bottled water to tide us through the night, and we just didn’t do any dishes and went to the camp toilets when necessary. Normally I like to travel with 5-10 gallons or so in the fresh water tank, but I forgot to fill it this time.
The rain finally stopped at some point in the night, which made me happy about the possibilities of being able to fly my drones, although the race has a history of dawning sunny and light winds, and it whipping up to a gale and rain just a few minutes before start time.
Next morning, the KOA camp store opened at 9, and they had drinking water hose. So we got the trailer hooked up and were able to flush toilets and wash dishes again. That was one burden off my mind. Also got to try the new Rhino Adaptor Pro – I’d been searching all over the internet for one of these things after they got announced this spring, and finally got one last week by driving 40 minutes away to a Walmart that had two of them. It’s everything I’d hoped – it makes a good water and smell tight seal with the sewage connection so you don’t have to pile rocks or sandbags to keep the “stinky slinky” from slipping out.
Unfortunately we didn’t pay attention to the time and we ended up leaving the campground just slightly too late to make the start of the race, so I headed straight to the one and only place where the race goes under a road bridge, on Rte 3 between First Pond and Second Pond. We parked up there and I trudged into the woods and set up to launch and retrieve my drone there. And really none too early, because the first paddlers showed up about 15-20 minutes later.
Uncharacteristically for ‘Round The Mountain, the weather stayed good for the whole race, with very little wind and no rain. It was overcast, which is a slight bummer because I love the video you get when it’s blue skies and sunny.
Like I said, I set up kind of in the wood where I had a good view over First Pond, but there was somebody else with a drone on or near the bridge, and sometimes I got thrown off by the sound of a drone coming from my right when I knew my drone was to my left. I don’t think I’ve ever encountered that before.
I spent nearly an hour videoing there, until I saw what I assumed was a sweeper boat. In my racing days, I was always up near the pointy end of the race, and I was pretty much laser focused on one or two other kayaks who I’d consider rivals, and every other boat out there was just an obstacle to pass or a potential wake to try to ride. So I was kind of amazed how many boats there were in the race, especially how many pack boats.
After that, we drove down to the finish and I did some more videoing there. I didn’t stay to the end there. But I got another half hour or so of video, and then packed up my drone. Met some old friends who were in the race, and invited them out to dinner.
Before dinner we went back to the campsite to rest up and change. I also spend some time working on the level problem. Did some googling, and found a document about setting up the In-Command system, which controls all the fancy stuff on the trailer, like the lights and the jacks and the furnace. And it described a way of manually extending and retracting the levels using a rotary switch and button on the In-Command circuit board. What I didn’t realize was that this method still used the relay, but sometimes ignorance is bliss because on the second attempt I got this button to actually retract the front jacks. Just after I did that, Steve came back on-line long enough to tell me that my problem was probably a relay, and the In-Command circuit board has a couple of spare relays below the in-use relays. I swapped the relay and now I could extend and retract the jacks with the app, and suddenly I wasn’t worried about anything any more.
We went out for dinner with Roger and Jim and Kim. It was a new brew-pub place in Saranac Lake and very popular, so there was a long wait to get seated – but interestingly enough, the wait list was managed in the Yelp app which told you how many people were ahead of you and your expected seating time. The food was excellent, and the beers on tap were pretty good, although Jim didn’t like his and switched to a Bud Lite. Can’t fault a guy for knowing what he likes, but he was pretty annoyed that they didn’t comp him the beer he didn’t like and only drank a few sips from.
Next morning was blue skies and sunshine, although the wind was a little higher. I was tempted to send the drone up to get pictures of the campground, but I figured I had enough video editing to do and I didn’t need to do any more. Plus Vicki had taken a bunch of pictures.
The drive home was also uneventful and more pleasant than the drive out. And RVLife didn’t try to kill us this time.
It’s now Friday, and in that time I’ve only managed to edit the First Pond footage. I still have the finish line footage to deal with. I was going to make one long video but I decided it had been long enough so I duplicated the project and cut off the unedited second part and uploaded that to YouTube. It isn’t terrible, if I do say so myself.