There’s been a couple of times when I’ve gotten paranoid about the fact that my truck is slightly over some of the weight limits when I’m towing the trailer. I think I’m exceeding the GVWR of the truck, and the rear axle GAWR. I’m also close to exceeding the “maximum tow capacity”. I’ve been assured by a friend who is a professional trucker that it’s not the case that under the number you’re fine and 1 pound over and you’re going to end up in a fiery wreck. But I also started hearing a new high pitched whine from under the hood and I started worrying that the engine doesn’t like the load I’m putting on it.
By the way, as an aside, can I just say two things to vehicle manufacturers:
You should be required to make a manual that just applies to this vehicle, not to every possible model of every car or truck you sell, ie not including pages about options and trim packages that aren’t on this particular vehicle. It should be like an aircraft manual where if you buy an option, you get given the pages about that option to insert in the manual.
If important information (like the towing capacity) is given as a URL, that URL should be legally required to still be available up to 25 years after the vehicle is sold, regardless of how many times you redesign your website.
Ok, so a couple of times I’ve had a look at Carvana to look at what’s available in the 3/4 ton and 1 ton pickup truck field. But none of the listings list anything about GVWR or GAWR. Most of them will list the payload value, but none of the other stuff from the door frame sticker. How hard would it be to include pictures of the door frame sticker amongst all the other pictures they provide? They have close-ups of every little discoloration or scratch, but not this vital information for a potential cargo or tow vehicle.
Another thing that’s hard to find is whether or not they have a 7 pin adaptor plug for towing an RV. Some will explicitly come out and say that they have the 4 pin adaptor plug for towing a cargo trailer, but not the 7 pin. And I don’t think that’s entirely Carvana’s fault – if you look up my VIN on the MOPAR site, it will tell you that it has “TRAILER TOW W/4-PIN CONNECTOR WIRING” in one place, and “7 PIN WIRING HARNESS” in another, and “TRAILER BRAKE CONTROL” in another, but it doesn’t actually come out and say it has a 7 pin connector.
And I don’t see any way to request that missing information. Which means if I do end up buying a new truck, I’m going to have to actually go to a dealer and look at what they have. But right now the trade-in value of my truck is plummeting faster than I’m making payments on it, so trading up is not something that I’m likely to do soon.
When we first bought the truck, there were a couple of small niggles – the sunroof doesn’t open and there is a bit of trim hanging off. Actually, there was a near disaster which we didn’t discover until we’d towed our new travel trailer home, which is that there was no power coming through the 7 pin plug to the trailer’s brake lights and one of the turn signals. Turns out that was just a couple of fuses, and now I carry a bunch of spare fuses in the truck for both the truck and the trailer.
At the time I bought it, I told them repeatedly that I didn’t care about the sunroof as long as they got it fixed before spring. Well, it’s summer and it’s still not fixed, but again I haven’t been bugging them. That should change.
My truck has these neat little boxes on the sides called “RamBoxes”. They’re kind of like saddlebags where you can toss tools and parts and stuff. They lock and unlock with the key fob, but I’ve discovered twice now that the locking mechanism uses these little plastic pivot points to transfer the movement of the servos from one direction to the other, and they’re fragile as hell. First one broke I think because I tried to unlock it when it was frozen, and the second one I might have hit the fob and pushed the button at the same time. First one I fixed by buying a replacement from the dealer – which took some faffing around and visiting two dealers. There are plenty of videos showing how to do this. Second one, I discovered a Reddit post saying you could use a metal throttle linkage instead of the fragile plastic, and that’s what I tried. So far, it’s working.
Last week, I had to replace both rear tires, when it appears an old patch that nobody told me about seemed to let go.
Today, I noticed that there was a cable hanging down. I had no idea what it was, so I posted it on Facebook and my brother identified it as the emergency brake cable. And lo and behold, there are literally dozens of videos, reddit posts and Ram forum questions about this, and it appears that there is a part of the emergency brake that seizes and needs to be freed by hand. One video I watched suggested using penetrating oil, another suggested baby oil from freshly squeezed babies, and my brother suggested lithium grease. I’ll have to give it a try.
The Leaf
We’ve had a problem, it started off intermittently and now it seems to be permanent. When you plug in the charger, it would beep and flash the charging lights in groups of 3. Googling found dozens of hits that suggest this only happens with Nissan Leafs. But some people were blaming the chargers, and some were blaming the Leafs. A lot of suggestions to take the charging handle apart to make sure the clamp is working right. The clamp on our charger didn’t seem to failing, and there wasn’t any way to take the handle apart.
We tried charging it once using the trickle charger plugged into the plug socket in the garage. Vicki was not satisfied with the speed, because in about 16 hours it only charged about 3/4 the way. Which is about right, because the manual says it should take 24 hours for a full charge. So we were looking at a future of having to charge it every day or every time we used it, instead of once every 3 or 4 days. But the second time we tried, we discovered that there was no power anywhere in the garage. More about that later.
After some reading and some experimentation, I discovered that if I put the charger handle in, then go into the car settings and change the “EV Charging Lock” from “Automatic” to “Locked”. It appears I’ll have to change it to “Unlocked” when it’s done charging so I can remove the charger handle again.
That’s a work-around for now, but I really want to fix this. And my research suggests that the problem is that there are some plastic bits in the locking mechanism that can wear out. And some suggest Nissan will admit that there’s a problem and replace them, but others suggest Nissan will charge up to $700 to fix it. And one person provided some files to 3d print replacements. If only I had a 3d printer, and knew how to replace those parts. Sigh.
The Garage
As stated above, we’ve got no electricity in the garage. This is unfortunate because we’ve got an electric lawnmower to charge up, plus when we bring the trailer home to load up, we plug it in so we can run the air conditioner. (We don’t have a big enough inverter or enough battery to run the A/C off the batteries.) And we’d still like to keep the trickle charger as an option for the Leaf if our current work-around stops working.
Of course, I tried resetting the breaker for the garage service. Also one of the outlets on the outside of the garage was a GFCI, so Vicki tried resetting that as well. I’ve done all these things multiple times, and no luck. Our next step is to call an electrician, which in Vicki’s mind means “invite an electrician she knows, his wife and children over for a special halal dinner” which I’m sure means there will be lots of productive work being done towards our problem.
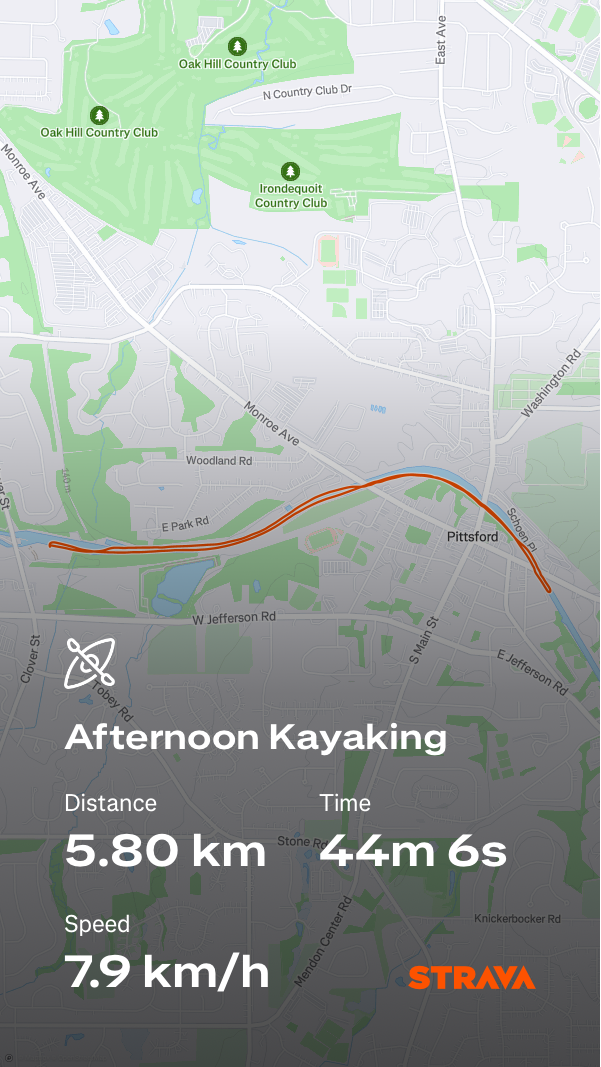
I got a pretty late start on paddling this year. It’s not like when I was racing – I remember one year when somebody asked me when my off season was, and I checked Garmin Connect and told them I hadn’t done any paddling between December 16th and January 6th, so I guess that was it. Between the fact that there were no races to train for, and this spring has been rainy and cold, there just weren’t any opportunities.
Today was my third paddle of the season. Last time, I went for 40 minutes and my physiotherapist Emma suggested I stick on that level of effort for a while. But I couldn’t help it – I paddled down for 20 minutes, knowing it would take a bit longer to come back because I’d had a tail wind. But the way back was very hard – I assumed because of the wind. I ended up taking a few breaks, and my shoulders were quite sore. I went into full “Boyan-mode”, paddling with my elbows down and almost no movement in my shoulders. But I was still completely done when I finished. I had to take another break before I could even lift the boat out of the water.
It was only after I got my boat on the roof rack that I noticed the rudder flag. “Hey, I don’t remember putting that on….come to think of it, I don’t remember taking it off…oh, and it’s soaking wet!” Yes, I’d inadvertently given myself some extra drag.
When I was racing, some of the real hard core types would put a rope with a knot or two on it around their boat, or even a couple of tennis balls, just for extra drag and more training effect. Knowing how fragile my shoulders are, there was no way I would participate in this madness. The closest I’d come was to switch to a wider boat, especially when training out on Lake Ontario. A little extra drag, a lot more stability, and I could really put the power down even in waves.
Last weekend (May 9-11) we did an RV trip to the Lake Placid/Saranac Lake area. Originally I’d planned to just do it on my own, because my main purpose for doing it was so I could shoot some drone footage at the ‘Round The Mountain Canoe/Kayak Race. They should probably rename that, because it’s not just canoes and kayaks, it’s also pack boats (a canoe-like boat with a lot of tumblehome so it’s paddled with a kayak paddle – most of them are made by Placid Boat Works) and guide boats (a bigger boat, rowed by one person, and sometimes with a person in the stern with a canoe paddle, based on the boats that Adirondak guides used a hundred years ago) and stand up paddle boards. I thought Vicki would be bored if I dragged her along but not only did she come on the trip, but she came to the race as well.
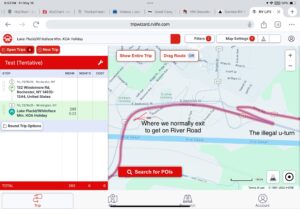
Anyway, we had a rainy drive up on Friday. RVLife once again tried to kill us by trying to route us via an illegal U-turn on a divided highway with almost no median between the directions, just a gap in the fence and a “No U-turns except emergency vehicles” sign. It’s funny, because mere minutes before this we passed an exit that I said “I normally go off here when using Google or Apple Maps, I wonder why RVLife is having us miss it?”
We arrived at the campground just a few minutes late for a normal check in. Some of the KOA people were still hanging around the late check in desk and handed us our mirror tag and camp map with the route to our campsite helpfully drawn in. It was a pull-through site, full service. Something we haven’t had yet this year. I pulled through, and checked our trailer location and declared it in proper position, so we set about leveling and unhitching and putting down the jacks and out the slides. But when it came time to hook up the water service, I discovered that the thing I’d thought was the water spigot was just some other piece of infrastructure, and the spigot was actually on the backside of the electrical post. And wouldn’t you know it, the water hose ended up being 4 feet short. Oh well, I thought, it’s a pain but I guess we’ll have to hitch up again and move the trailer back 4 feet.
That’s when disaster struck. The front set of jacks wouldn’t retract. The relay made a click, but there was no motor sound. So now we’ve got two problems, and no easy way to fix them. The Facebook technical guru Steve was also camping, and both of us had intermittent 1 dot of signal. But he said to try resetting everything, but that didn’t work. Also it turned out that the manual retraction of the jacks uses a proprietary connection, and evidently we didn’t get one with our trailer, or misplaced it. So we decided that we had to get some more drinking water hose.
We drove into Lake Placid and Saranac Lake, and didn’t find any place selling garden hose. We did stop at a grocery store and bought some bottled water to tide us through the night, and we just didn’t do any dishes and went to the camp toilets when necessary. Normally I like to travel with 5-10 gallons or so in the fresh water tank, but I forgot to fill it this time.
The rain finally stopped at some point in the night, which made me happy about the possibilities of being able to fly my drones, although the race has a history of dawning sunny and light winds, and it whipping up to a gale and rain just a few minutes before start time.
Next morning, the KOA camp store opened at 9, and they had drinking water hose. So we got the trailer hooked up and were able to flush toilets and wash dishes again. That was one burden off my mind. Also got to try the new Rhino Adaptor Pro – I’d been searching all over the internet for one of these things after they got announced this spring, and finally got one last week by driving 40 minutes away to a Walmart that had two of them. It’s everything I’d hoped – it makes a good water and smell tight seal with the sewage connection so you don’t have to pile rocks or sandbags to keep the “stinky slinky” from slipping out.
Unfortunately we didn’t pay attention to the time and we ended up leaving the campground just slightly too late to make the start of the race, so I headed straight to the one and only place where the race goes under a road bridge, on Rte 3 between First Pond and Second Pond. We parked up there and I trudged into the woods and set up to launch and retrieve my drone there. And really none too early, because the first paddlers showed up about 15-20 minutes later.
Uncharacteristically for ‘Round The Mountain, the weather stayed good for the whole race, with very little wind and no rain. It was overcast, which is a slight bummer because I love the video you get when it’s blue skies and sunny.
Like I said, I set up kind of in the wood where I had a good view over First Pond, but there was somebody else with a drone on or near the bridge, and sometimes I got thrown off by the sound of a drone coming from my right when I knew my drone was to my left. I don’t think I’ve ever encountered that before.
I spent nearly an hour videoing there, until I saw what I assumed was a sweeper boat. In my racing days, I was always up near the pointy end of the race, and I was pretty much laser focused on one or two other kayaks who I’d consider rivals, and every other boat out there was just an obstacle to pass or a potential wake to try to ride. So I was kind of amazed how many boats there were in the race, especially how many pack boats.
After that, we drove down to the finish and I did some more videoing there. I didn’t stay to the end there. But I got another half hour or so of video, and then packed up my drone. Met some old friends who were in the race, and invited them out to dinner.
Before dinner we went back to the campsite to rest up and change. I also spend some time working on the level problem. Did some googling, and found a document about setting up the In-Command system, which controls all the fancy stuff on the trailer, like the lights and the jacks and the furnace. And it described a way of manually extending and retracting the levels using a rotary switch and button on the In-Command circuit board. What I didn’t realize was that this method still used the relay, but sometimes ignorance is bliss because on the second attempt I got this button to actually retract the front jacks. Just after I did that, Steve came back on-line long enough to tell me that my problem was probably a relay, and the In-Command circuit board has a couple of spare relays below the in-use relays. I swapped the relay and now I could extend and retract the jacks with the app, and suddenly I wasn’t worried about anything any more.
We went out for dinner with Roger and Jim and Kim. It was a new brew-pub place in Saranac Lake and very popular, so there was a long wait to get seated – but interestingly enough, the wait list was managed in the Yelp app which told you how many people were ahead of you and your expected seating time. The food was excellent, and the beers on tap were pretty good, although Jim didn’t like his and switched to a Bud Lite. Can’t fault a guy for knowing what he likes, but he was pretty annoyed that they didn’t comp him the beer he didn’t like and only drank a few sips from.
Next morning was blue skies and sunshine, although the wind was a little higher. I was tempted to send the drone up to get pictures of the campground, but I figured I had enough video editing to do and I didn’t need to do any more. Plus Vicki had taken a bunch of pictures.
The drive home was also uneventful and more pleasant than the drive out. And RVLife didn’t try to kill us this time.
It’s now Friday, and in that time I’ve only managed to edit the First Pond footage. I still have the finish line footage to deal with. I was going to make one long video but I decided it had been long enough so I duplicated the project and cut off the unedited second part and uploaded that to YouTube. It isn’t terrible, if I do say so myself.
The day started at sometime between 4 and 5 AM when Gizmo puked on the bed. Through the duvet cover, through the duvet, through the sheets and through the mattress cover. We stripped off the duvet and top sheet, put a towel over the bottom sheet, and went back to sleep.
When we woke up for real, we discovered the travails of getting the trailer parked had all been worth it, because all the door side windows were facing a fantastic view through the trees to the lake and at the “mountain” on the other side.
After a nice breakfast of oatmeal with raspberries and blackberries, we took the dogs for a walk around the lake. Thanks to Riot, we had to just sort of shrug in apology to all the people with dogs who he barked his head off at, but we met several people who enjoyed his enthusiastic greetings. We met our camp hosts about half way around where they were sitting on some picnic tables where they could get a data connection. Sadly not our network – our phones continued to do the “now you see it, now you don’t” trick of showing one bar of 5G or LTE, then reverting to “SAT” or “SOS”. We sometimes manage to get off a SMS or receive one by connecting to Starlink, but it’s not something you can count on all the time.
After the walk, we headed into town to wash the sheets and duvet, and also to stop at the Giant for to replace the food we forgot in the freezer when we left. On the way down on Monday, the truck had popped up a warning that it was time for an oil change, but sadly there was no quick oil change places in town. There were regular service stations, but I didn’t want to have to call around and see who could fit us in. So we spent the time between cycles sitting in the truck catching up on social media.
On the way into down, we’d been on a very long downhill behind a big truck that was going 20mph (as required by the signage). I used the buttons on the steering wheel to downshift and use engine braking, but sadly when we got to the bottom of the hill I couldn’t figure out how to get it back into automatic mode, so instead I waited until a stop sign and put it in neutral and back into drive. I suppose I should have looked online how to do that when we were catching up, but I had important stuff to do, like find out who had liked my posts.
Afterwards, we spent some time just sitting out under our awning, enjoying the view and sipping our drinks. Since my Facebook feed is full of clips from the DockTok dads, I felt like we should be telling dad jokes to each other, but neither of us could think of any. Riot continued his job of making enemies of everyone with dogs and friends of anybody without.
It was a pretty quiet and restful afternoon and evening, until the foreshadowed disaster happened and while I was washing dishes the drains stopped draining. I was unsure if that was just “we have a clog” or “oh oh, the grey tank is full”, but then the bathroom sink drain stopped draining, so it’s the grey tank thing for sure. (The people who thought the bathroom sink was connected to the black tank can suck it, we win that bet.) Which means first thing Wednesday we’re going to have to hitch up and go take the trailer out to the dump station, and then have all the fun of backing into this space again. Ugh.